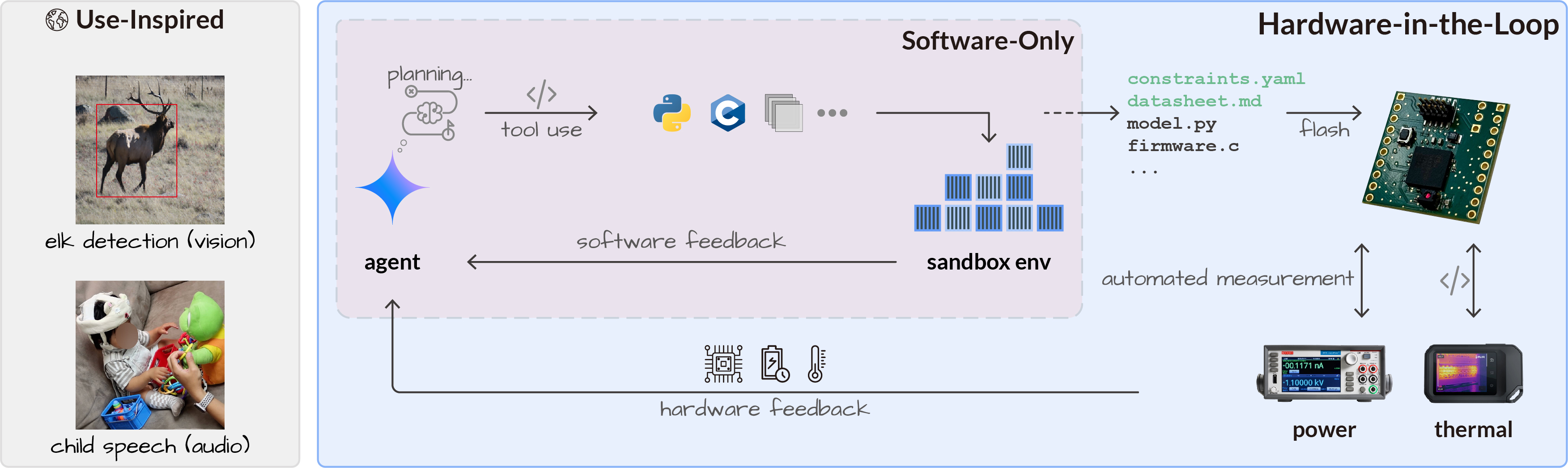
Embedded devices from wildlife monitoring stations to clinical wearables require local AI inference due to latency, communication, or privacy constraints. Optimizing models for heterogeneous microcontrollers (MCUs) requires simultaneously satisfying hard physical constraints on memory, power, and temperature while preserving accuracy, a multidimensional optimization that is today performed manually by experts. We ask whether an LLM agent can autonomously navigate this complex, multi-turn pipeline guided by real hardware feedback, and introduce a hardware-in-the-loop agent arena in which the agent iteratively refines both model and firmware -- compiling, flashing, and measuring on real hardware -- to enable closed-loop optimization. Frontier models, including Claude Opus 4.7 and Gemini 3.1 Pro, fail entirely without hardware feedback (0% deployment success), whereas our hardware-in-the-loop formulation achieves the first successful deployment within three iterations and can surpass human expert results within seven. This agentic co-optimization achieves 250x compression for vision models with <3.3% accuracy loss and 400x for audio with <6% Feature Error Rate loss, enabling battery-free operation on a commercial MCU via solar harvesting. We demonstrate practical impact in two real-world systems: an elk-detection camera trap (96.7% accuracy) and a phonetic-transcription wearable (8.44% FER) for child development research.
Embedded Arena: Iterative Optimization via Hardware Feedback
 University of Washington
University of Washington
 University of California San Diego
University of California San Diego
 Northeastern University
*Equal contribution
Northeastern University
*Equal contribution